")
The web moves at a breakneck pace. Websites get updates and redesigns all the time. In some cases, information gets lost in that process, whether that’s because a site has been taken down or simply due to improper storage.
Online historical records enable you to see old versions of websites, captured at specific moments in time. Being able to do that is useful for more than just taking trips down memory lane, so let’s talk about internet archives!
Subscribe To Our Youtube Channel
Why You’d Want to See Old Versions of Websites
There are plenty of reasons you might want to see old versions of your favorite (or most used) websites. On many sites, a lot of things change over time, including:
- Their overall design
- The data you have access to
- Specific pages that get deleted or updated
Consider our own website, for example. It has been around since 2008, and as you might imagine, a lot of things have changed since its early days:

Being able to peek into the past is incredibly helpful. You can find design inspiration in old websites, and get access to media files that are no longer available.
More importantly, however, internet archives enable you to see information that has been lost to time. For example, if one of your favorite websites goes offline, you should be able to find a stored copy of it around the web:
Having access to old versions of websites also enables you to circumvent censorship in some cases. If your Internet Service Provider (ISP) or government censors parts of the web, you might be able to get past those barriers and look at archived sites.
Beyond the more practical reasons, it’s essential that we keep a record of the web as it was and is today. Internet archives fulfill a similar function to libraries, enabling us to peek into the past and see how things have changed over time.
3 Tools You Can Use to See Old Versions of Websites
There are a surprising number of services that store or cache old copies of websites. In most cases, they take ‘snapshots’ of specific sites and pages upon request. That means you can end up with an archive that saves thousands of copies of your website over time, depending on its popularity. Let’s check out some of these services and what they have to offer.
1. Internet Archive’s Wayback Machine
The Internet Archive is a nonprofit organization, which is dedicated to building a digital library of websites, books, audio recordings, videos, images, and even software. If you’re looking to kill a little time, the Internet Archive even hosts emulated versions of old games that you can play right from your browser:
As far as websites go, the Internet Archive stores over 448 billion pages, and you can navigate them using its Wayback Machine tool:
To get started, enter the URL of the website you want to check out. The Wayback Machine will show you a graph that tracks how often copies of that website were saved over the years. If you click on a specific year within that graph, you’ll be able to access individual copies of the site using a calendar:
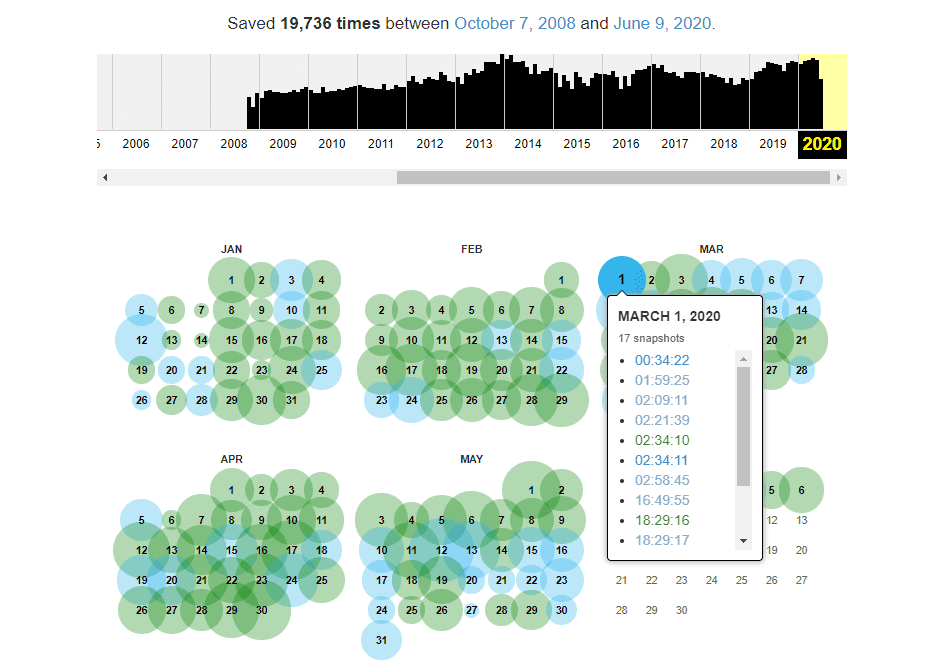
To give you an idea of how thorough an archive this is, the Wayback Machine has saved over 19,700 copies of the Elegant Themes website.
Once you select what snapshot you want to see, the Wayback Machine will load that cached copy in a new tab:
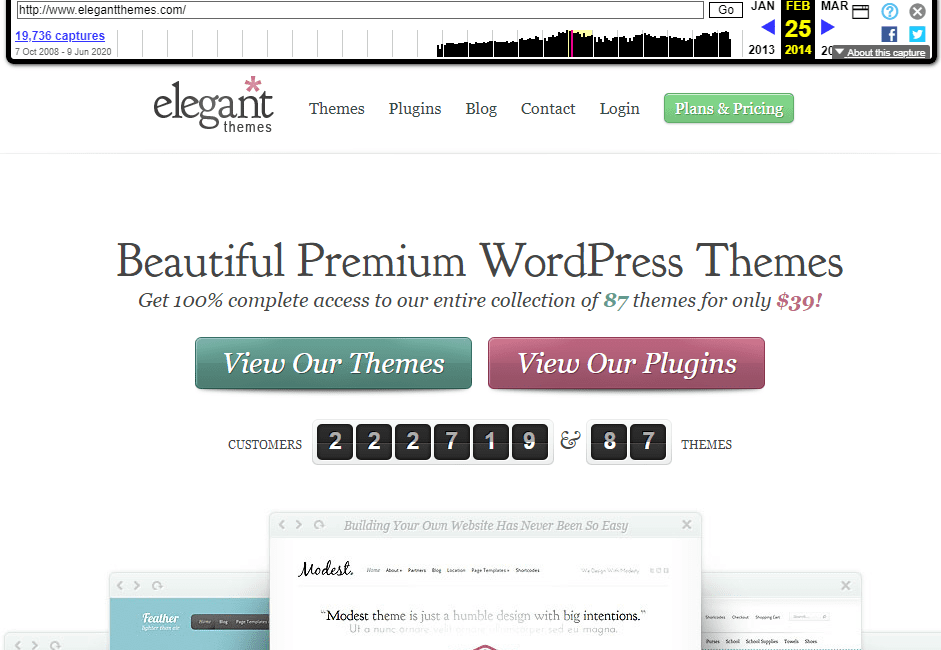
Keep in mind that loading times probably won’t be as fast as you’re used to. Once the page loads, however, you should be able to interact with it as usual. You can move from page to page, save images, read comments, etc.
In some cases, though, you won’t be able to navigate within old cached copies of a website. That’s because some pages that are linked to might not be cached, which is common for sites with massive content libraries.
2. oldweb.today
oldweb.today is a service that enables you to load copies of old websites, while emulating old browsers to give you the full experience. If you never had the joy of using Netscape or ancient versions of Internet Explorer, oldweb.today can help you scratch that itch.
This service pulls copies of the pages you want to see from third-party archives. Those include the Internet Archive and national libraries from around the world, making for a pretty comprehensive service.
As you might expect, though, emulating old browsers and pulling data from several sources takes time. oldweb.today often requires you to wait in a virtual line before you can see what you want:
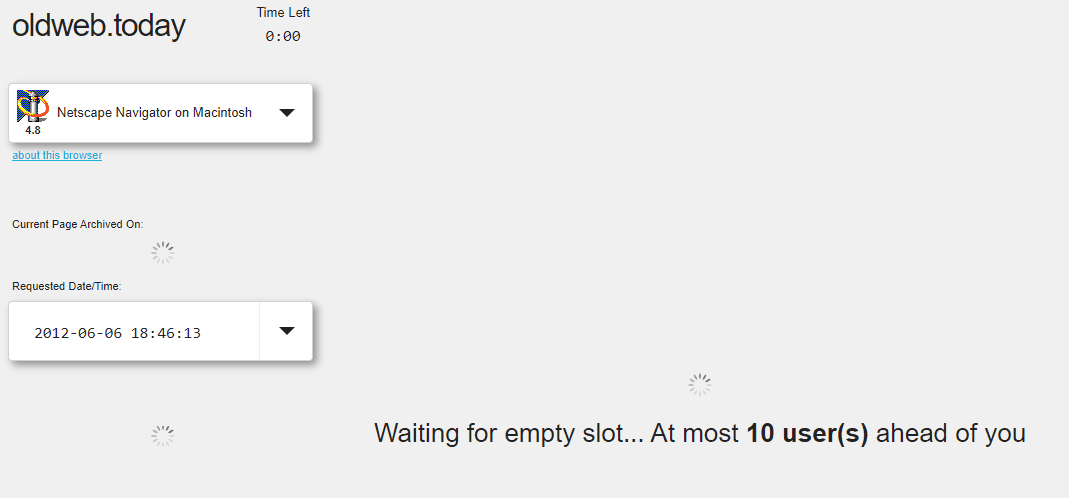
Once the wait is over, the service will launch an emulated version of the browser you chose, displaying the website you wanted to see:
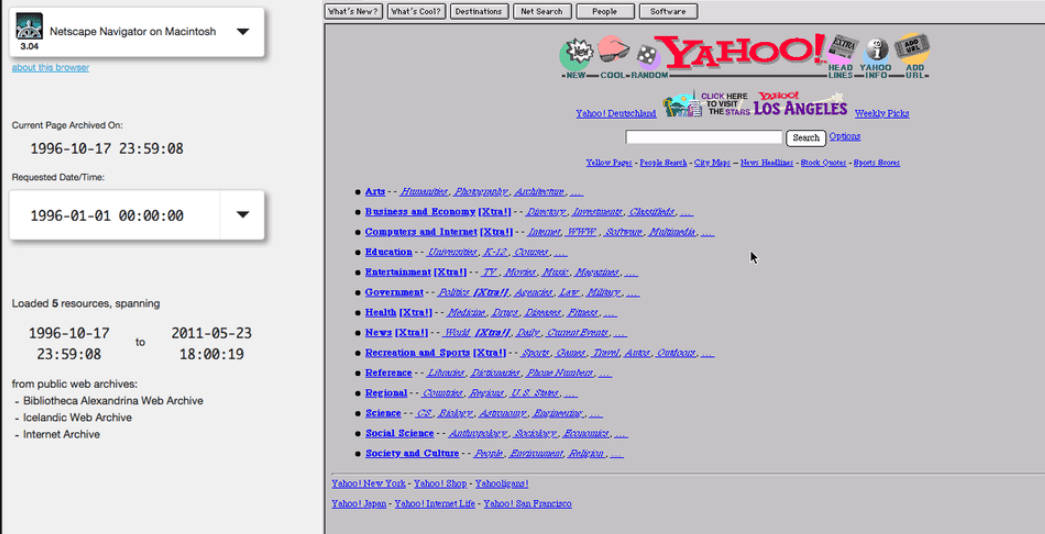
As fun as it can be to browse old websites, the wait times mean that oldweb.today isn’t as great an option if you want to check out multiple versions of the same site. The wait can often go on for minutes, so that time adds up pretty quickly.
3. Library of Congress
The American Library of Congress houses the largest collection of books, recordings, newspapers, and websites in the world. Its website collection works differently than our previous two suggestions, though.
If you try looking up a specific website using the library’s search feature, you’ll probably find a collection of haphazard results. Here’s what appears when we look up “reddit”, for example:
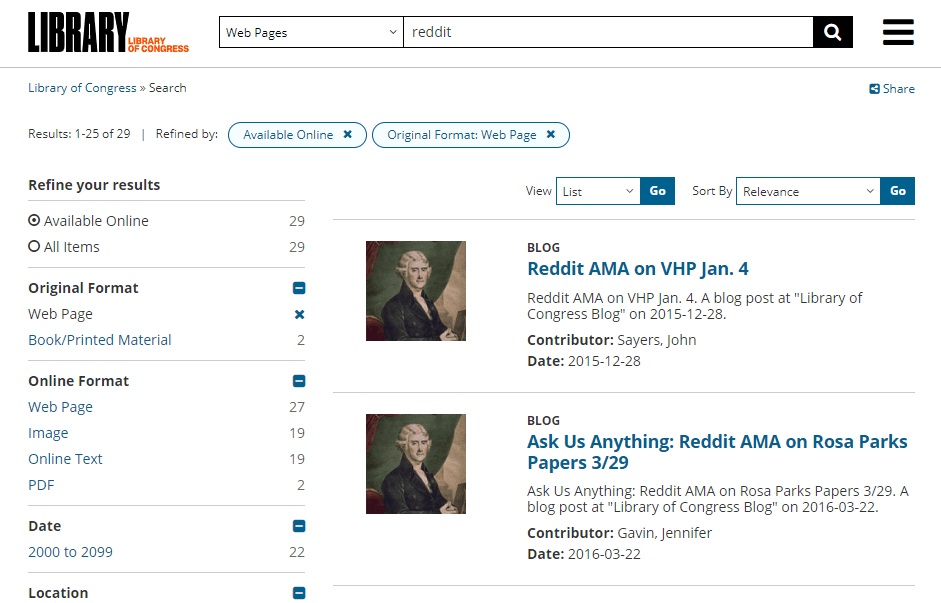
When you open individual links, the library enables you to browse the pages it has in storage, using a system identical to the Wayback Machine:
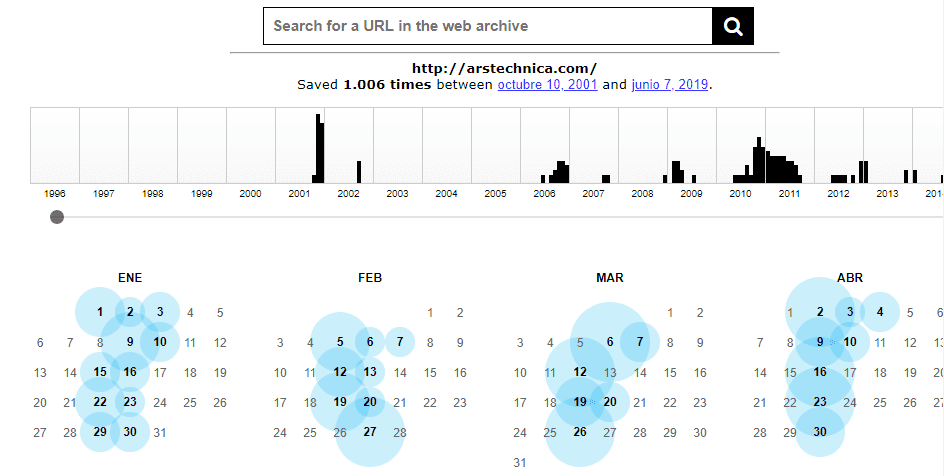
The library also saves descriptions and other useful information for every website in its archive, which makes it particularly useful for research:

Likewise, you can browse the archive itself without running a search, as the library offers an in-depth category system that includes all of its entries:
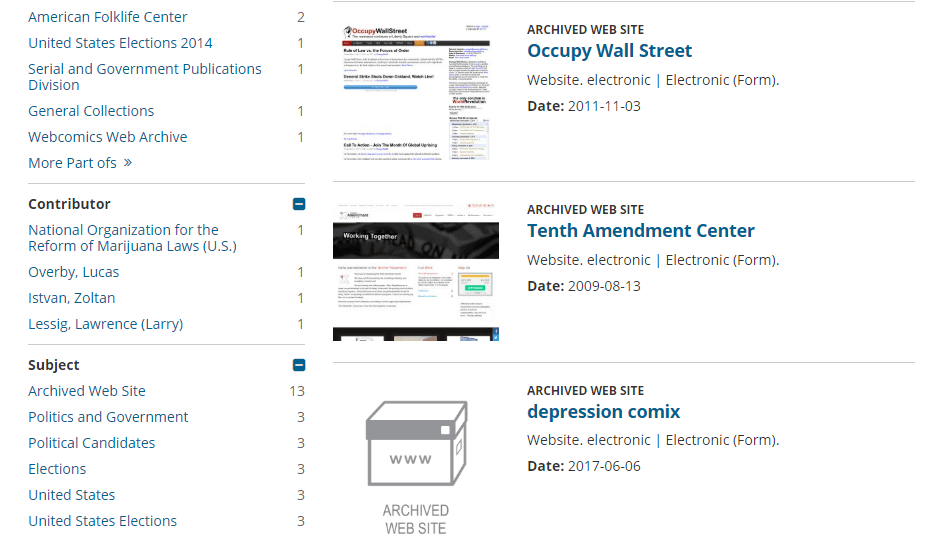
Although the library’s website archive isn’t as extensive as the Wayback Machine’s, it offers a lot more detail. The library also lets you browse around without a particular website in mind, which is something other archives don’t enable you to do.
On another note, this library also houses a huge collection of images that you’re free to use, sometimes without attribution:
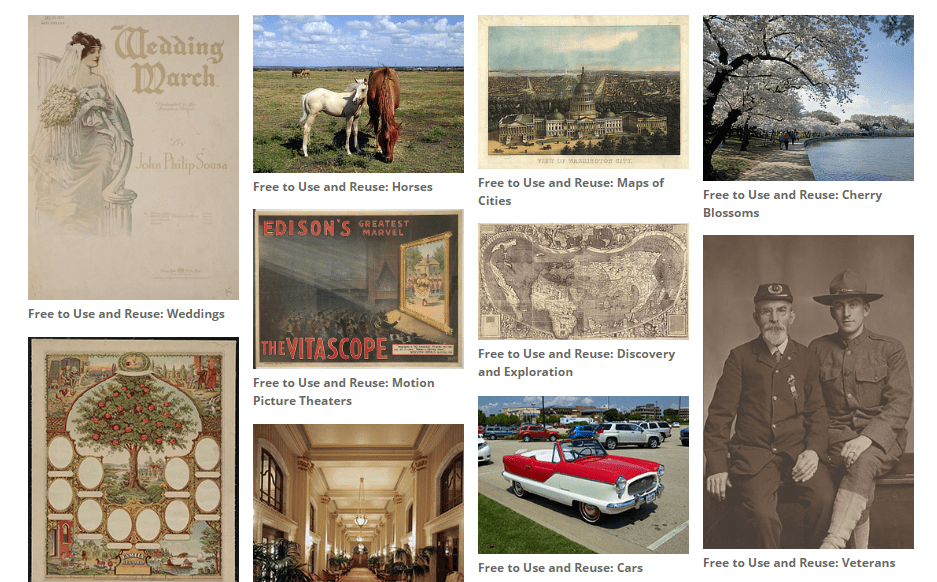
Some of these sets are images from the web. That makes this site a valuable resource for stock graphics, if you ever grow bored of more traditional options.
Conclusion
There are a lot of practical reasons you’d want to take a look at old versions of specific websites. Perhaps you’re hunting for content that’s no longer there and images you want to re-use, or maybe you’re just trying to bypass censorship.
In any case, internet archives fulfill a great public service for all of us. Here are your three best options if you want to peek into the past of the web:
- Internet Archive’s Wayback Machine: Navigate the largest archive of cached pages on the web.
- oldweb.today: Use emulated versions of old browsers to navigate websites from the past.
- Library of Congress: Browse the library using an in-depth category system, or take a look at specific websites.
What’s your favorite old website that’s no longer around? Share your memories in the comments section below!
Article thumbnail image by Leremy / shutterstock.com



I usually check version of webserver over network request. Example: if a website using PHP 7 I will know it’s version
Thanks for the insight, trangtriquangcao. We’re referring here to viewing content that’s no longer publically available online, but there are certainly advantages to noting PHP version as well!
Wow it’s really awesome to see how some webs looked like… Another knowledge gained…
Happy to help, Eking.
The Wayback Machine is really useful. Most of the people scrap out the content from the website and refurbish into their own language and then share it across various social media platforms to get huge amount of traffic. The tools listed here gives an enormous idea about old web pages.
Interesting stuff, Ali. Glad you liked the post.
Ditto to Lana: I love me some Wayback Machine!
I checked the history of many sites with this site, it was very interesting
Glad you think so, Tabriz.
The Wayback Machine has saved the day many times. I’m glad it’s there!
So are we, Lana!